

Behind the Curtain is a monthly column from Chloe Grutchfield of Redbud, digging deep each month to discover what’s really going on buried deep in the adtech ecosystem
Since the Financial Times article “How top health websites are sharing sensitive data with advertisers” was published, a plethora of other publications have followed suit, with sometimes apocalyptic headlines on how UK publishers are monetising their readers’ health problems. A few worried clients of ours got in touch with us to understand if they were inadvertently allowing special category data – derived from their users’ browsing behaviour – to be sold to advertisers.
The simple answer? No.
In 99.9% of cases, publishers are not knowingly or intentionally selling a user’s personal health data, and most vendors are not trying to build audiences off of special category data. Why? The risk is too high versus the benefits. Hello, GDPR?!
The way the web was built, and the current programmatic advertising ecosystem has created a landscape full of cracks. The industry is working hard (believe me, we have attended countless meetings to understand how we can help to improve) but we need to be better. That’s undeniable.
But in order to be better, we need to decipher fact from fiction.
Let’s take a look at the Special Category data breach and what happened.
Website Search Capabilities
Most websites have a search capability that allows users to find articles that match their particular interest. So, for testing purposes, I decided to search for “fertility problems” across a range of websites – not just health-related websites.
Since the damning article came from the FT, naturally I started there. The irony is that FT is actually a victim of one of the issues that is called out in the article itself.
Upon entering the keywords “fertility problems”, I land on a page https://www.ft.com/search?q=fertility+problems. Several things are happening in the background:
- An ad/bid request is sent to advertising partners (including Google) and the URL is sent as part of the request (that’s standard)
- Other trackers that are triggered on the site (either through direct implementation or via redirects) also receive the URL (except if they are part of a “safe frame”, which tends to happen with vendors that are involved in the serving and tracking of an ad)
Here is an illustrative screenshot to show the URL with the special category keywords sent within a Google API call as I’m browsing the FT search results:
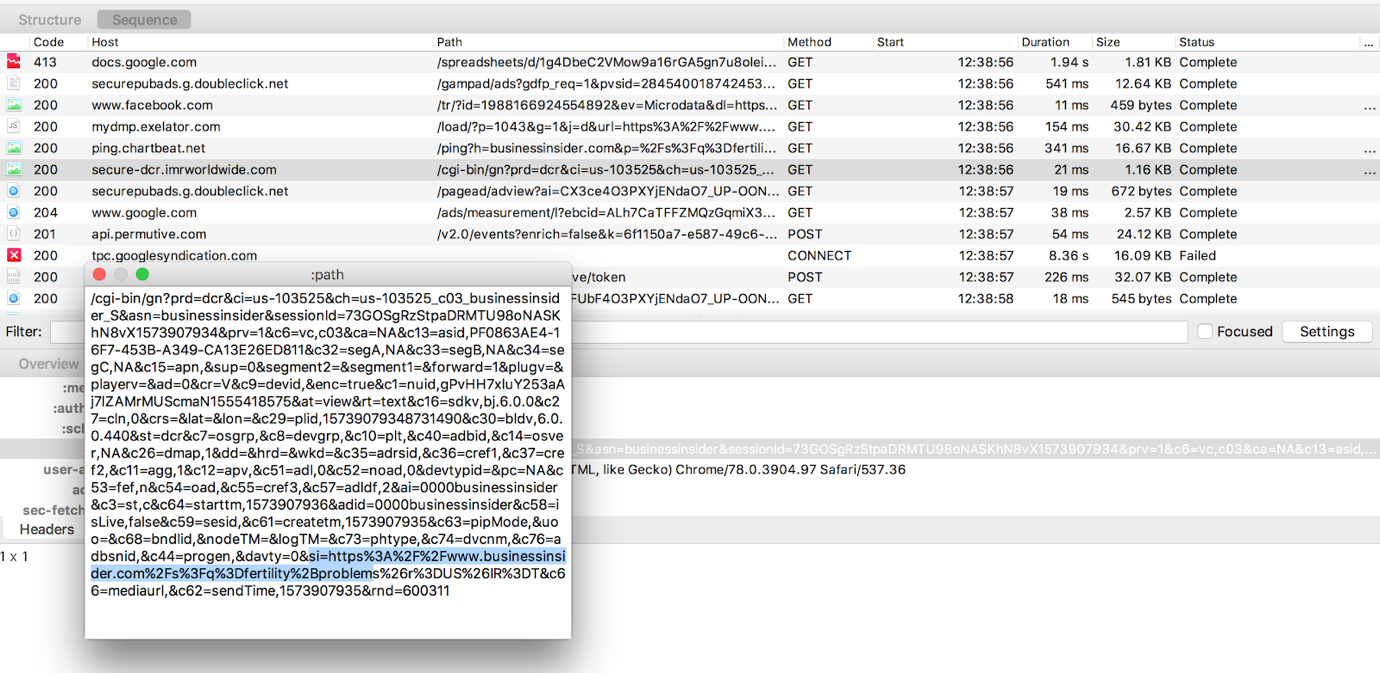
This is not restricted to advertising technology by the way. Any tracker implemented on site for whatever purpose (functional, analytics, measurement etc.) will get a “referrer” URL in the HTTP request and therefore access to this URL (unless they are triggered via a safe frame).
This URL doesn’t allow any vendor to single out an individual, unless they are able to drop a cookie that stores an ID which is also saved on the vendor’s database, server side.
You see where I’m going with this: vendors get the URL (with sensitive information) and in some instances drop a cookie that singles out the individual. Nefarious vendors may be extracting keywords to build audience profiles based off of the search term, therefore putting my cookie in the bucket of “fertility problems”.
The inevitable question then follows; Who are they going to monetise this to?
Privacy health companies? I would imagine they have rigorous processes to vet vendors and those vendors wouldn’t pass their privacy checklist. Perhaps they are going through a data aggregator? Yes, that’s also possible. But most have strict privacy vetting processes too.
I do think that there’s a big risk here, but I like to think that with GDPR, most businesses have strict processes in place to ensure that only data with the appropriate consent is used. There’s just too much to lose. And therefore, I don’t know if we can really talk about a “breach”.
There will always be criminals – with or without cookies — throughout programmatic advertising. The key is in keeping a very close eye on them.
What Can We do?
There are a few things that can be done by publishers to limit the risk:
- Change the way that URLs are built in the CMS to obfuscate special category-related keywords contained in articles
- Change the search functionality so that search terms aren’t passed onto the URL
- Javascript triggered on page can scan for the content of a particular page – understand which scripts are triggered directly and from who and whether they are triggered via a safe frame
The industry as a whole need to revisit things to bring risk as close to 0 as possible. I can’t help but see parallels with the accounting world pre-Sarbanes Oxley Act. The Sarbanes-Oxley Act of 2002 was setup to prevent fraudulent activity by implementing rules and procedures for corporate governance and accountability. I think we need to introduce more audits in our industry to understand where the cracks are and sort them.





